在Scrapy專案中可以使用Item與Item Pipeline來儲存並處理所擷取的資料。前者是專案的資料模型,可以在items.py檔案中定義欄位來儲存爬取的資料;後者是處理抓取Item資料的機制,在pipelines.py檔案中可以過濾、驗證、轉換和清除從Item截取下的資料。兩者的檔案在新增專案時會一並建立。
items.py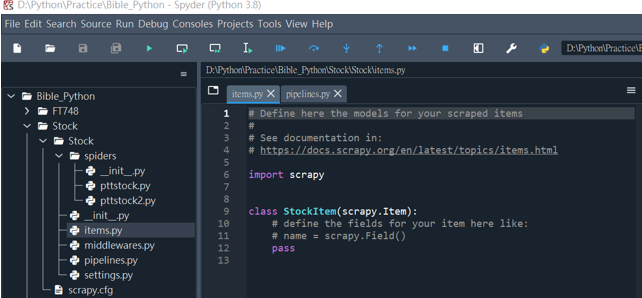
pipelines.py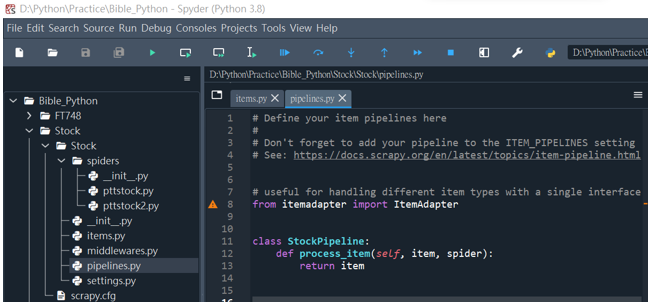
以擷取批批踢股票看板的發文標題、推文數和作者資料為例來做演練。
import scrapy
class StockItem(scrapy.Item):
# 定義Item欄位
title = scrapy.Field()
vote = scrapy.Field()
author = scrapy.Field()
pass
from scrapy.exceptions import DropItem
class StockPipeline(object):
def process_item(self, item, spider): #處理推文數資料
if item["vote"]:
if item["vote"] == "爆":
item["vote"] = 500
else:
item["vote"] = int(item["vote"])
return item
else:
raise DropItem("沒有推文數: %s" % item)
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'Stock.pipelines.StockPipeline': 300,
}
import scrapy
from Stock.items import StockItem
class Pttstock2Spider(scrapy.Spider):
name = 'pttstock2'
allowed_domains = ['ptt.cc']
start_urls = ['https://www.ptt.cc/bbs/Stock/index5438.html']
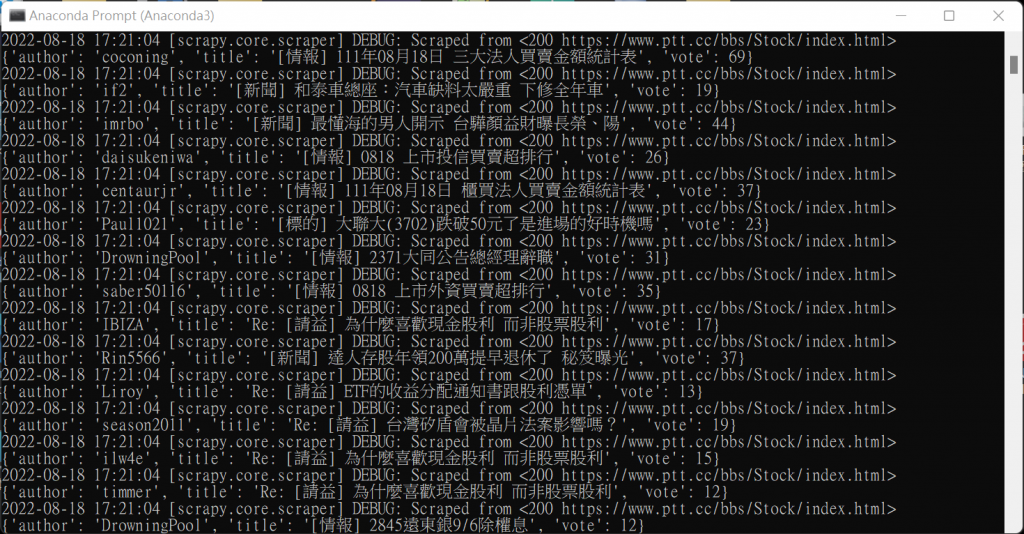
def parse(self, response):
for sel in response.css(".r-ent"):
#定位文章標題、推文數與作者的位置並擷取出放入item項目中
item = StockItem()
item["title"] = sel.css("div.title > a::text").extract_first()
item["vote"] = \
sel.xpath("./div[@class='nrec']/span/text()").extract_first()
item["author"] = \
sel.xpath("./div[@class='meta']/div[1]/text()").extract_first()
yield item


 iThome鐵人賽
iThome鐵人賽